Onderzoekers op het gebied van kunstmatige intelligentie hebben met succes een machine learning-model ontwikkeld dat woorden kan leren met behulp van beelden die zijn vastgelegd door een kind dat een camera op het hoofd draagt. De bevindingen, deze week gepubliceerd in Wetenschaphet zou een nieuw licht kunnen werpen op de manier waarop kinderen taal leren en mogelijk de inspanningen van onderzoekers kunnen informeren om toekomstige machine learning-modellen te bouwen die meer als mensen leren.
Uit eerder onderzoek is gebleken dat kinderen de eerste woordjes beginnen te leren rond de leeftijd van zes tot negen maanden. Op hun tweede verjaardag heeft het gemiddelde kind ongeveer 300 woorden in zijn woordenschat. Maar de feitelijke mechanismen die precies ten grondslag liggen aan de manier waarop kinderen betekenis associëren met woorden blijven onduidelijk en het onderwerp van wetenschappelijk debat. Onderzoekers van het Center for Data Science van de Universiteit van New York probeerden dit grijze gebied verder te verkennen door een model voor kunstmatige intelligentie te creëren dat op dezelfde manier probeerde te leren als een kind.
Om het model te trainen, vertrouwden de onderzoekers op meer dan 60 uur video en audio vastgelegd door een lichthoofdige camera die was bevestigd aan een kind genaamd Sam. De peuter droeg de camera aan en uit vanaf zes maanden en eindigend na zijn tweede verjaardag. Gedurende die 19 maanden verzamelde de camera meer dan 600.000 videoframes gekoppeld aan meer dan 37.500 getranscribeerde verklaringen van mensen uit de buurt. Achtergrondgeluiden en camerabeelden geven inzicht in de ervaringen van het zich ontwikkelende kind terwijl het eet, speelt en in het algemeen de wereld om hem heen ervaart.
Gewapend met de ogen en oren van Sam creëerden de onderzoekers vervolgens een neuraal netwerkmodel om te proberen te begrijpen wat Sam zag en hoorde. Het model, dat één module had die individuele frames van de camera analyseerde en een andere module gericht was op getranscribeerde spraak rechtstreeks naar Sam, stond onder zelfbeheer, wat betekent dat er geen gebruik werd gemaakt van externe gegevenslabels om objecten te identificeren. Net als een kind leerde het model door woorden te associëren met specifieke objecten en beelden wanneer deze zich tegelijkertijd voordeden.
“Door AI-modellen te gebruiken om het echte taalleerprobleem waarmee kinderen worden geconfronteerd te bestuderen, kunnen we klassieke debatten aangaan over welke ingrediënten kinderen nodig hebben om woorden te leren – of ze nu taalvooroordelen, aangeboren kennis of gewoon associatief leren nodig hebben om aan de slag te gaan”, zegt co. -auteur van het artikel en NYU Center for Data Science-professor Brenden Lake zei in een verklaring. “Het lijkt erop dat we door alleen maar te leren meer kunnen winnen dan vaak wordt gedacht.”
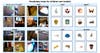
De onderzoekers testten het model op dezelfde manier waarop wetenschappers kinderen beoordelen. De onderzoekers presenteerden het model vier afbeeldingen uit een trainingsset en vroegen het om te kiezen welke overeenkwam met een bepaald woord, zoals ‘bal’, ‘wieg’ of ‘boom’. Het model was 61,6% van de tijd succesvol. Het met de babycamera getrainde model benaderde zelfs een vergelijkbaar nauwkeurigheidsniveau als een paar afzonderlijke AI-modellen die met veel meer taalkundige input waren getraind. Nog indrukwekkender was dat het model sommige beelden correct kon identificeren die niet in de cameradataset van Sam waren opgenomen. Dit suggereert dat het model kon leren van de gegevens waarop het was getraind en deze kon gebruiken om meer algemene observaties te maken.
“Deze bevindingen suggereren dat dit aspect van het leren van woorden kan worden afgeleid van het soort naturalistische gegevens dat kinderen verwerven bij het gebruik van relatief generieke leermechanismen zoals die gevonden in neurale netwerken”, aldus Lake.
Met andere woorden: het vermogen van het AI-model om objecten consistent te identificeren met behulp van alleen gegevens van de hoofdcamera laat zien hoe representatief leren, of simpelweg het associëren van beelden met gelijktijdige woorden, voldoende lijkt te zijn voor kinderen om te leren en woordenschat te verwerven.
De bevindingen wijzen op een alternatieve methode voor het trainen van AI
Kijkend naar de toekomst kunnen de bevindingen van de NYU-onderzoekers waardevol blijken voor toekomstige AI-ontwikkelaars die geïnteresseerd zijn in het creëren van AI-modellen die op een mensachtige manier leren. De kunstmatige-intelligentie-industrie en computerwetenschappers gebruiken het menselijk denken en neurale paden al lang als inspiratie voor het bouwen van AI-systemen.
Onlangs hebben grote taalmodellen zoals het OpenAI GPT-model of Google’s Bard bewezen dat ze nuttige essays kunnen schrijven, code kunnen genereren en periodiek feiten kunnen breken dankzij een intensieve trainingsperiode waarin de modellen biljoenen parameters aan gegevens injecteren die uit enorme datasets zijn gehaald. De bevindingen van NYU suggereren echter dat een alternatieve methode voor woordverwerving mogelijk zou kunnen zijn. In plaats van te vertrouwen op massa’s mogelijk auteursrechtelijk beschermde of bevooroordeelde input, zou een AI-model dat de manier nabootst waarop mensen leren wanneer we door de wereld kruipen en struikelen, een alternatieve route naar taalherkenning kunnen bieden.
“Ik was verrast hoeveel de hedendaagse kunstmatige intelligentiesystemen kunnen leren als ze worden blootgesteld aan de vrij minimale hoeveelheid gegevens die een kind daadwerkelijk ontvangt bij het leren van een taal”, zegt Lake.