In 1997 IBM diepblauw een supercomputer versloeg de wereldkampioen schaken Garry Kasparov. Het was een revolutionaire demonstratie van supercomputertechnologie en de eerste glimp van hoe high-performance computing eruit ziet stroom op een dag de mens inhalen–niveau van intelligentie. In de daaropvolgende tien jaar zijn we kunstmatige intelligentie voor veel praktische taken gaan gebruiken, zoals gezichtsherkenning, taalvertaling en aanbevelingen voor films en merchandise.
Nog eens anderhalf decennium vooruit en AI is zo ver gevorderd dat het ‘kennis kan synthetiseren’. Generatieve AI, zoals ChatGPT en Stable Diffusion, kan liedjes componeren, illustraties maken, ziekten diagnosticeren, beknopte rapporten en computercode schrijven, en zelfs geïntegreerde schakelingen ontwerpen die kunnen wedijveren met die van mensen.
Er zijn enorme mogelijkheden voor kunstmatige intelligentie om een digitale assistent te worden bij alle menselijke inspanningen. ChatGPT is een goed voorbeeld van hoe AI het gebruik van high-performance computing heeft gedemocratiseerd en voordelen heeft opgeleverd voor elk individu in de samenleving.
Al deze prachtige AI-toepassingen zijn tot stand gekomen dankzij drie factoren: innovaties in efficiënte machine learning-algoritmen, de beschikbaarheid van enorme hoeveelheden gegevens waarop neurale netwerken kunnen worden getraind, en vooruitgang op het gebied van energie-efficiënt computergebruik door vooruitgang in de halfgeleidertechnologie. Deze nieuwste bijdrage aan de generatieve AI-revolutie heeft, ondanks de alomtegenwoordigheid ervan, een minder dan redelijk deel gekregen.
De afgelopen drie decennia zijn alle belangrijke mijlpalen op het gebied van AI mogelijk gemaakt door de geavanceerde halfgeleidertechnologie van die tijd, en zonder deze zouden ze onmogelijk zijn geweest. Deep Blue wordt geïmplementeerd met behulp van een combinatie van chipproductietechnologie van 0,6 en 0,35 micrometer. Het diepe neurale netwerk dat de ImageNet-wedstrijd won en het huidige tijdperk van machinaal leren inluidde, werd geïmplementeerd met 40-nanometertechnologie. AlphaGo won het spel Go met behulp van 28-nm-technologie, en de eerste versie van ChatGPT werd getraind op computers die waren gebouwd met 5-nm-technologie. De nieuwste versie van ChatGPT wordt mogelijk gemaakt door servers die nog geavanceerdere 4nm-technologie gebruiken. Elke laag van de betrokken computersystemen, van software en algoritmen tot architectuur, circuitontwerp en apparaattechnologie, fungeert als een vermenigvuldiger voor AI-prestaties. Maar het is eerlijk om te zeggen dat de onderliggende technologie van transistorapparaten de bovenste lagen mogelijk heeft gemaakt.
Als de AI-revolutie in het huidige tempo doorgaat, zal er zelfs meer nodig zijn dan de halfgeleiderindustrie. Binnen tien jaar zal er een GPU nodig zijn met 1 biljoen transistors, dat wil zeggen een GPU met 10 keer meer apparaten dan tegenwoordig gebruikelijk is.
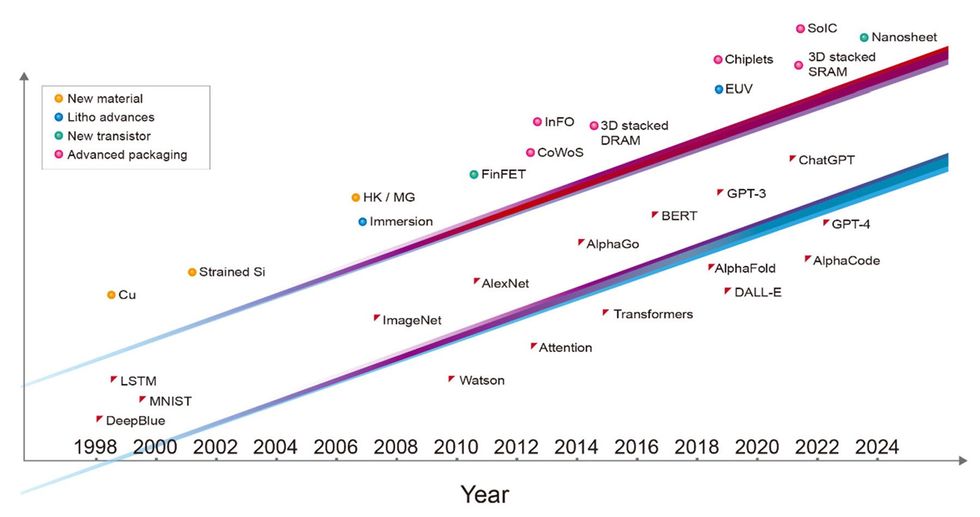 Vooruitgang in halfgeleidertechnologie [top line]– inclusief nieuwe materialen, vooruitgang in de lithografie, nieuwe typen transistors en geavanceerde verpakkingen – hebben de ontwikkeling van capabelere AI-systemen aangewakkerd [bottom line]
Vooruitgang in halfgeleidertechnologie [top line]– inclusief nieuwe materialen, vooruitgang in de lithografie, nieuwe typen transistors en geavanceerde verpakkingen – hebben de ontwikkeling van capabelere AI-systemen aangewakkerd [bottom line]
Meedogenloze groei in AI-modelgroottes
De reken- en geheugentoegang die nodig is om AI te trainen, is de afgelopen vijf jaar met ordes van grootte toegenomen. Het trainen van GPT-3 vereist bijvoorbeeld het equivalent van meer dan 5 miljard miljard rekenbewerkingen per seconde gedurende een hele dag (dat zijn 5.000 petaflops-dagen) en 3 biljoen bytes (3 terabytes) aan geheugencapaciteit.
Zowel de rekenkracht als de geheugentoegang die nodig is voor nieuwe generatieve AI-toepassingen blijven snel groeien. Nu moeten we de prangende vraag beantwoorden: hoe kan de halfgeleidertechnologie gelijke tred houden?
Van geïntegreerde apparaten tot geïntegreerde chiplets
Sinds de uitvinding van de geïntegreerde schakeling draait het bij de halfgeleidertechnologie om het verkleinen van de featuregroottes, zodat we meer transistors in een chip van miniatuurformaat kunnen proppen. Tegenwoordig is de integratie een niveau hoger gegaan; we gaan verder dan 2D-schaling naar 3D-systeemintegratie. Nu assembleren we veel chips tot een strak geïntegreerd, enorm onderling verbonden systeem. Dit is een paradigmaverschuiving in de integratie van halfgeleidertechnologie.
In het tijdperk van AI is de capaciteit van een systeem recht evenredig met het aantal transistors dat in dat systeem is geïntegreerd. Een van de belangrijkste beperkingen is dat gereedschappen voor het maken van lithografische chips zijn ontworpen om IC’s niet groter te maken dan ongeveer 800 vierkante millimeter, wat de draadlimiet wordt genoemd. Maar nu kunnen we de omvang van het geïntegreerde systeem uitbreiden tot voorbij de grenzen van de lithografie. Door meerdere chips aan een grotere interposer te bevestigen – het stuk silicium waarin de verbindingen zijn ingebed – kunnen we een systeem integreren dat een veel groter aantal apparaten bevat dan mogelijk is op één enkele chip. De chip-on-wafer-on-substrate (CoWoS) -technologie van TSMC kan bijvoorbeeld maximaal zes computerchips in een threadveld huisvesten, samen met een tiental HBM-chips (high-bandwidth memory).
HBM’s zijn een voorbeeld van een andere belangrijke halfgeleidertechnologie die steeds belangrijker wordt voor AI: het vermogen om systemen te integreren door chips op elkaar te stapelen, wat wij bij TSMC noemen systeem op geïntegreerde chips (SoIC). De HBM bestaat uit een stapel verticaal met elkaar verbonden DRAM-chips erop en controle logisch IC. Er wordt gebruik gemaakt van zogenaamde verticale verbindingen Tdoor-Silikon-CIAS (TSVS) om het signaal door elke chip te krijgen en de bobbels te solderen om de verbindingen tussen de geheugenchips te vormen. Tegenwoordig gebruiken krachtige GPU’s HBMuitgebreid.
In de toekomst kan 3D SoIC-technologie een “hobbelloos alternatief” bieden voor de conventionele HBM-technologie van vandaag, waardoor een veel dichtere verticale verbinding tussen gestapelde chips ontstaat. Recente ontwikkelingen hebben HBM-teststructuren laten zien met 12 lagen chips gestapeld met behulp van hybride binding, koper-op-koperverbindingen met een hogere dichtheid dan soldeerhobbels kunnen bieden. Dit geheugensysteem is bij lage temperatuur verbonden met een grotere onderliggende logica-chip en heeft een totale dikte van slechts 600 µm.
Met een krachtig computersysteem dat bestaat uit een groot aantal matrices die grote AI-modellen aansturen, kan snelle bekabelde communicatie de rekensnelheid snel beperken. Tegenwoordig worden optische verbindingen al gebruikt om serverracks in datacenters met elkaar te verbinden. Binnenkort hebben we optische interfaces nodig op basis van siliciumfotonica, samen met GPU’s en CPU’s. Dit maakt energie- en ruimte-efficiënte schaalvergroting van de bandbreedte mogelijk voor directe, optische GPU-naar-GPU-communicatie, zodat honderden servers kunnen fungeren als één gigantische GPU met verenigd geheugen. Door de vraag naar AI-toepassingen zal siliciumfotonica een van de belangrijkste technologieën worden die de halfgeleiderindustrie mogelijk maken.
Op weg naar een biljoen transistor-GPU
Zoals al opgemerkt, hebben typische GPU-chips die voor AI-training worden gebruikt de limiet van het draadveld al bereikt. En hun aantal transistors is ongeveer 100 miljard apparaten. De voortzetting van de trend van het vergroten van het aantal transistors zal meer chips vereisen, onderling verbonden door 2,5D- of 3D-integratie, om berekeningen uit te voeren. De integratie van meerdere chips, hetzij via CoWoS of SoIC en gerelateerde geavanceerde verpakkingstechnologieën, maakt een veel groter totaal aantal transistors per systeem mogelijk dan in één enkele chip kan worden gepropt. We voorspellen dat een multichiplet-GPU binnen tien jaar meer dan 1 biljoen transistors zal hebben.
We zullen al deze chips met elkaar moeten verbinden in een 3D-stack, maar gelukkig is de industrie erin geslaagd de hoogte van verticale verbindingen snel te verkleinen, waardoor de dichtheid van verbindingen toeneemt. En er is nog genoeg ruimte voor meer. Wij zien geen reden waarom de interconnectiedichtheid niet met een orde van grootte of zelfs meer zou kunnen groeien.
Energie-efficiënte prestatietrend voor GPU’s
Dus hoe dragen al deze innovatieve hardwaretechnologieën bij aan de systeemprestaties?
We kunnen al een trend zien in server-GPU’s als we kijken naar de gestage verbetering van een maatstaf die energie-efficiënte prestaties wordt genoemd. EEP is een gecombineerde maatstaf voor energie-efficiëntie en systeemsnelheid. De afgelopen vijftien jaar heeft de halfgeleiderindustrie haar energie-efficiënte prestaties elke twee jaar met ongeveer drie keer verhoogd. Wij geloven dat deze trend zich in een historisch tempo zal voortzetten. Het zal worden aangedreven door innovatie uit vele bronnen, waaronder onder meer nieuwe materialen, apparaat- en integratietechnologie, extreem ultraviolet (EUV) lithografie, circuitontwerp, systeemarchitectuurontwerp en co-optimalisatie van al deze technologische elementen.
De toename van de EEP zal met name mogelijk worden gemaakt door de geavanceerde verpakkingstechnologieën die hier worden besproken. Bovendien zullen concepten zoals systeemtechnologieco-optimalisatie (STCO), waarbij verschillende functionele delen van de GPU worden gescheiden in hun eigen chips en worden gebouwd met behulp van de beste prestaties en meest kosteneffectieve technologieën voor elk, steeds belangrijker worden.
Mead-Conway-moment voor 3D-geïntegreerde schakelingen
In 1978 vonden Carver Mead, een professor aan het California Institute of Technology, en Lynn Conway van Xerox PARC de computerondersteunde ontwerpmethode voor geïntegreerde schakelingen uit. Ze gebruikten een reeks ontwerpregels om de chipschaling te beschrijven, zodat ingenieurs gemakkelijk zeer grootschalige integratiecircuits (VLSI) konden ontwerpen zonder veel kennis van procestechnologie.
Dezelfde soort mogelijkheden zijn vereist voor het ontwerpen van 3D-chips. Tegenwoordig moeten ontwerpers kennis hebben van chipontwerp, systeemarchitectuurontwerp en hardware- en software-optimalisatie. Fabrikanten moeten kennis hebben van chiptechnologie, 3D IC-technologie en geavanceerde verpakkingstechnologie. Net als in 1978 hebben we opnieuw een gemeenschappelijke taal nodig om deze technologieën te beschrijven op een manier die elektronische ontwerptools begrijpen. Een dergelijke hardwarebeschrijvingstaal geeft ontwerpers de vrije hand om te werken aan het ontwerp van 3D IC-systemen, ongeacht de onderliggende technologie. Onderweg: een open source-standaard, 3Dblox genaamd, is al overgenomen door de meeste hedendaagse technologie- en elektronische ontwerpautomatiseringsbedrijven (EDA).
De toekomst achter de tunnel
In het tijdperk van kunstmatige intelligentie is halfgeleidertechnologie een belangrijke factor voor nieuwe AI-mogelijkheden en -toepassingen. De nieuwe GPU wordt niet langer beperkt door de standaardformaten en vormfactoren uit het verleden. Nieuwe halfgeleidertechnologie beperkt zich niet langer tot het verkleinen van transistors van de volgende generatie op een tweedimensionaal vlak. Een geïntegreerd AI-systeem kan bestaan uit zoveel energiezuinige transistors als praktisch mogelijk is, een efficiënte systeemarchitectuur voor gespecialiseerde computerwerklasten en een geoptimaliseerde relatie tussen software en hardware.
De afgelopen vijftig jaar voelde de ontwikkeling van halfgeleidertechnologie als het lopen in een tunnel. De weg die voor ons lag was duidelijk, aangezien het een duidelijk afgebakend pad was. En iedereen wist wat te doen: de transistor verkleinen.
We hebben nu het einde van de tunnel bereikt. Vanaf dit punt zal de ontwikkeling van halfgeleidertechnologie moeilijker worden. Maar buiten de tunnel zijn er nog veel meer mogelijkheden. We zijn niet langer gebonden aan het raamwerk van het verleden.