Het bijhouden van een snel evoluerende industrie als AI is een hele opgave. Dus hoewel AI het niet voor je kan doen, is hier een handig overzicht van recente verhalen in de wereld van machinaal leren, samen met opmerkelijk onderzoek en experimenten die we zelf niet hebben behandeld.
Deze week kondigde Amazon Rufus aan, een winkelassistent met kunstmatige intelligentie die is getraind in de productcatalogus van de e-commercegigant en informatie van internet. Rufus woont in de mobiele app van Amazon en helpt je producten te vinden, producten te vergelijken en aanbevelingen te krijgen over wat je kunt kopen.
Uit uitgebreid onderzoek aan het begin van een shoppingtrip zoals “Waar moet je op letten bij het kopen van hardloopschoenen?” tot vergelijkingen als ‘wat zijn de verschillen tussen trail- en weghardloopschoenen?’ … Rufus verbetert aanzienlijk hoe gemakkelijk het voor klanten is om de beste producten te vinden en te ontdekken die aan hun behoeften voldoen”, schreef Amazon in een blogpost.
Dat is allemaal geweldig. Maar mijn vraag is wie erom vraagt Echt?
Ik ben er niet van overtuigd dat GenAI, vooral in de vorm van een chatbot, een stukje technologie is waar de gemiddelde persoon om geeft – of zelfs maar over nadenkt. Opiniepeilingen steunen mij daarin. Afgelopen augustus ontdekte het Pew Research Center dat van degenen in de VS die hadden gehoord van OpenAI’s GenAI-chatbot ChatGPT (18% van de volwassenen), slechts 26% het had geprobeerd. Het gebruik varieert uiteraard per leeftijd, waarbij een hoger percentage jongeren (onder de 50) het gebruikt dan ouderen. Maar het feit blijft dat de overgrote meerderheid niet weet (of er niet om geeft) hoe ze dit misschien wel het populairste GenAI-product moeten gebruiken.
GenAI heeft zijn eigen veelbesproken problemen, waaronder de neiging om feiten te verzinnen, inbreuk op het auteursrecht, vooroordelen en toxiciteit. Amazon’s eerdere poging tot een GenAI-chatbot, Amazon Q, had het moeilijk: vertrouwelijke informatie werd al binnen de eerste dag na de release onthuld. Maar ik zou willen stellen dat het grootste probleem met GenAI op dit moment – althans vanuit consumentenperspectief – is dat er weinig universeel overtuigende redenen zijn om het te gebruiken.
Natuurlijk kan een GenAI als Rufus helpen met specifieke, beperkte taken zoals winkelen voor de gelegenheid (bijvoorbeeld het vinden van kleding voor de winter), het vergelijken van productcategorieën (bijvoorbeeld het verschil tussen lipgloss en olie) en het doen van topaanbevelingen (bijvoorbeeld cadeaus voor Valentijnsdag). dag). Voldoet het echter aan de behoeften van de meeste klanten? Niet volgens een recent onderzoek van e-commercesoftware Namogoo.
Namogoo, dat honderden consumenten vroeg naar hun behoeften en frustraties als het gaat om online winkelen, ontdekte dat productafbeeldingen veruit de belangrijkste bijdrage leveren aan een goede e-commerce-ervaring, gevolgd door recensies en productbeschrijvingen. Respondenten rangschikten zoeken als de vierde belangrijkste, en “gemakkelijke navigatie” als de vijfde; het onthouden van voorkeuren, informatie en aankoopgeschiedenis was op één na laatste.
De implicatie is dat mensen over het algemeen kopen met een product in gedachten; die zoektocht is een bijzaak. Misschien zal Rufus de vergelijking opschudden. Ik heb de neiging om dat niet te denken, vooral als het een zware uitrol is (en dat zou kunnen worden opgepikt door de andere GenAI-winkelexperimenten van Amazon) – maar ik denk dat er vreemdere dingen zijn gebeurd.
Hier zijn enkele andere interessante AI-verhalen van de afgelopen dagen:
- Google Maps experimenteert met GenAI: Google Maps introduceert de GenAI-functie waarmee u nieuwe plaatsen kunt ontdekken. Met behulp van grootschalige taalmodellen (LLM) analyseert deze functie meer dan 250 miljoen locaties op Google Maps en de input van meer dan 300 miljoen lokale gidsen om suggesties te geven op basis van wat u zoekt.
- GenAI-tools voor muziek en meer: In ander Google-nieuws bracht de technologiegigant GenAI-tools uit voor het maken van muziek, tekst en afbeeldingen en bracht Gemini Pro, een van zijn capabelere LLM’s, naar gebruikers van zijn Bard-chatbot over de hele wereld.
- Nieuwe open AI-modellen: Het Allen Institute for AI, een non-profit AI-onderzoeksinstituut opgericht door wijlen mede-oprichter van Microsoft Paul Allen, heeft verschillende GenAI-taalmodellen uitgebracht waarvan het beweert dat ze ‘opener’ zijn dan andere – en, belangrijker nog, op een zodanige manier gelicentieerd zijn dat ontwikkelaars kunnen onbelemmerd gebruiken voor training, experimenten en zelfs commercialisering.
- De FCC verbiedt oproepen gegenereerd door kunstmatige intelligentie: De FCC stelt voor om het gebruik van stemkloneringstechnologie bij robocalls volledig illegaal te maken, waardoor het gemakkelijker wordt om vervoerders kosten in rekening te brengen voor deze oplichting.
- Shopify presenteert een afbeeldingseditor: Shopify brengt GenAI-media-editor uit om productafbeeldingen te verbeteren. Handelaren kunnen een type kiezen uit zeven stijlen of een zoekopdracht invoeren om een nieuwe achtergrond te genereren.
- GPT’s, genaamd: OpenAI moedigt de adoptie aan van GPT, applicaties van derden die worden aangedreven door zijn AI-modellen, waardoor ChatGPT mogelijk wordt gemaakt gebruiker om ze uit te nodigen voor een chat. Betaalde ChatGPT-gebruikers kunnen GPT’s in het gesprek betrekken door “@” te typen en een GPT uit de lijst te selecteren.
- OpenAI in samenwerking met Common Sense: In een niet-gerelateerde aankondiging zei OpenAI dat het samenwerkt met Common Sense Media, een non-profitorganisatie die de geschiktheid van verschillende media en technologie voor kinderen beoordeelt en rangschikt, om samen te werken aan AI-richtlijnen en educatief materiaal voor ouders, opvoeders en jonge volwassenen.
- Autonoom browsen: Het bedrijf Browser, dat Arc Browser maakt, wil een kunstmatige intelligentie creëren die voor u op internet surft en u resultaten geeft terwijl u browsers omzeilt, schrijft Ivan.
Meer machinaal leren
Weet AI wat ‘normaal’ of ‘typisch’ is voor een bepaalde situatie, medium of uiting? In zekere zin zijn grote taalmodellen bij uitstek geschikt om te identificeren welke patronen het meest lijken op andere patronen in hun datasets. En inderdaad, dat is wat Yale-onderzoekers ontdekten in hun onderzoek naar de vraag of AI de ‘typische aard’ van iets in een groep anderen kan identificeren. Wat is bijvoorbeeld, gegeven 100 romans, het meest en wat het minst ‘typisch’, gegeven wat het model over dat genre heeft opgeslagen?
Interessant (en frustrerend) dat de professoren Balázs Kovács en Gaël Le Mens al jaren aan hun model, de BERT-variant, werkten, en net toen ze op het punt stonden te publiceren, kwam ChatGPT langs en dupliceerde in veel opzichten precies wat ze aan het doen waren. “Je zou kunnen huilen”, zei Le Mens in een persbericht. Maar het goede nieuws is dat zowel de nieuwe AI als hun oude, aangepaste model suggereren dat dit type systeem inderdaad kan identificeren wat typisch en atypisch is binnen een dataset, een bevinding die later nuttig zou kunnen zijn. De twee wijzen erop dat hoewel ChatGPT hun stelling in de praktijk ondersteunt, het gesloten karakter ervan wetenschappelijk werk moeilijk maakt.
Wetenschappers van de Universiteit van Pennsylvania keken naar een ander vreemd concept voor kwantificering: gezond verstand. Door duizenden mensen te vragen uitspraken als ‘je krijgt wat je geeft’ of ‘eet geen voedsel na de houdbaarheidsdatum’ te beoordelen op hoe ‘gezond verstand’ ze waren. Het is niet verrassend dat, hoewel er patronen naar voren kwamen, er “weinig overtuigingen werden erkend op groepsniveau”.
“Onze bevindingen suggereren dat ieders idee van gezond verstand uniek kan zijn, waardoor het concept minder gebruikelijk is dan je zou verwachten”, zegt co-auteur Mark Whiting. Waarom staat dit in de AI-nieuwsbrief? Omdat het, net als bijna al het andere, blijkt dat zoiets ‘eenvoudigs’ als gezond verstand, waar AI naar verwachting uiteindelijk over zal beschikken, helemaal niet eenvoudig is! Maar door het op deze manier te kwantificeren, zouden onderzoekers en auditors kunnen zien hoeveel gezond verstand de AI heeft, of met welke groepen en vooroordelen zij verbonden is.
Over vooroordelen gesproken: veel grote taalmodellen gaan nogal losjes om met de informatie die ze invoeren, wat betekent dat als je ze de juiste vraag stelt, ze kunnen reageren op manieren die aanstootgevend, onnauwkeurig of beide zijn. Latimer is een startup die daar verandering in wil brengen met een model dat is ontworpen om meer inclusief te zijn.
Hoewel er niet veel details zijn over hun aanpak, zegt Latimer dat hun model gebruik maakt van uitgebreide downloadgeneratie (bedoeld om de reacties te verbeteren) en een schat aan unieke gelicentieerde inhoud en gegevens uit een groot aantal culturen die normaal niet in deze databases vertegenwoordigd zijn. Dus als je ergens naar vraagt, gaat het model niet terug naar een monografie uit de 19e eeuw om je te antwoorden. We zullen meer over het model weten wanneer Latimer meer informatie vrijgeeft.
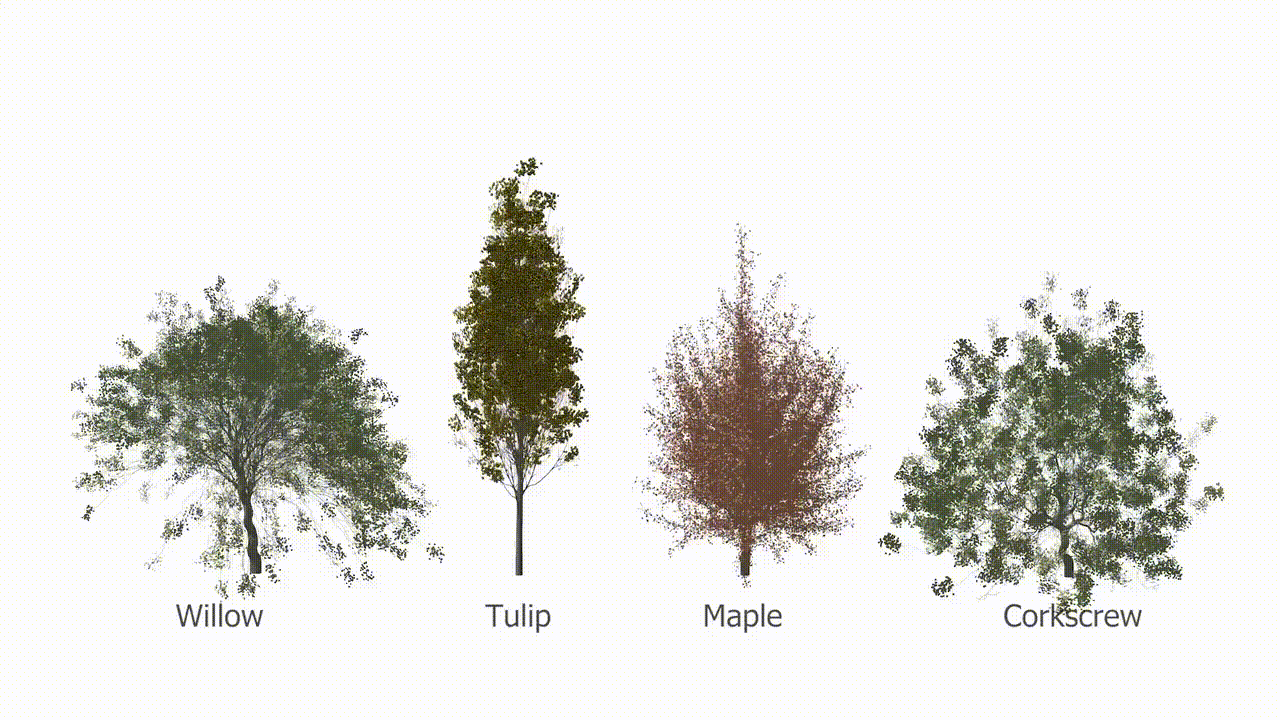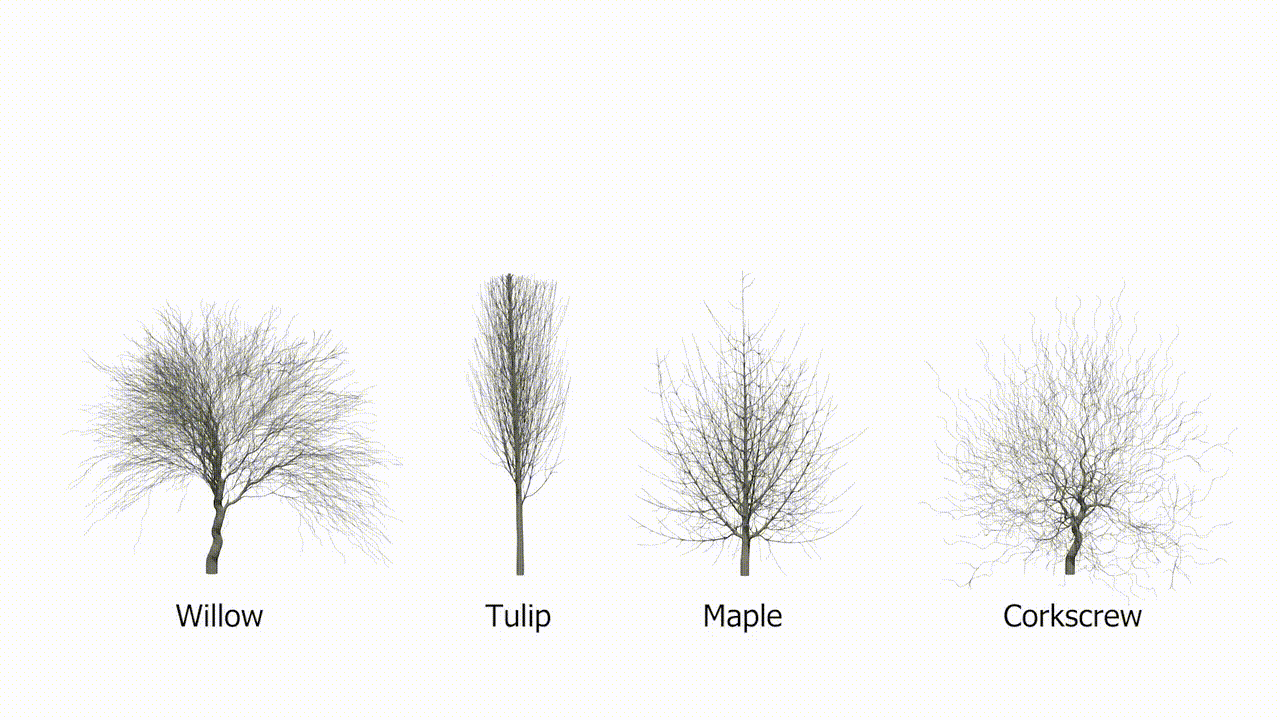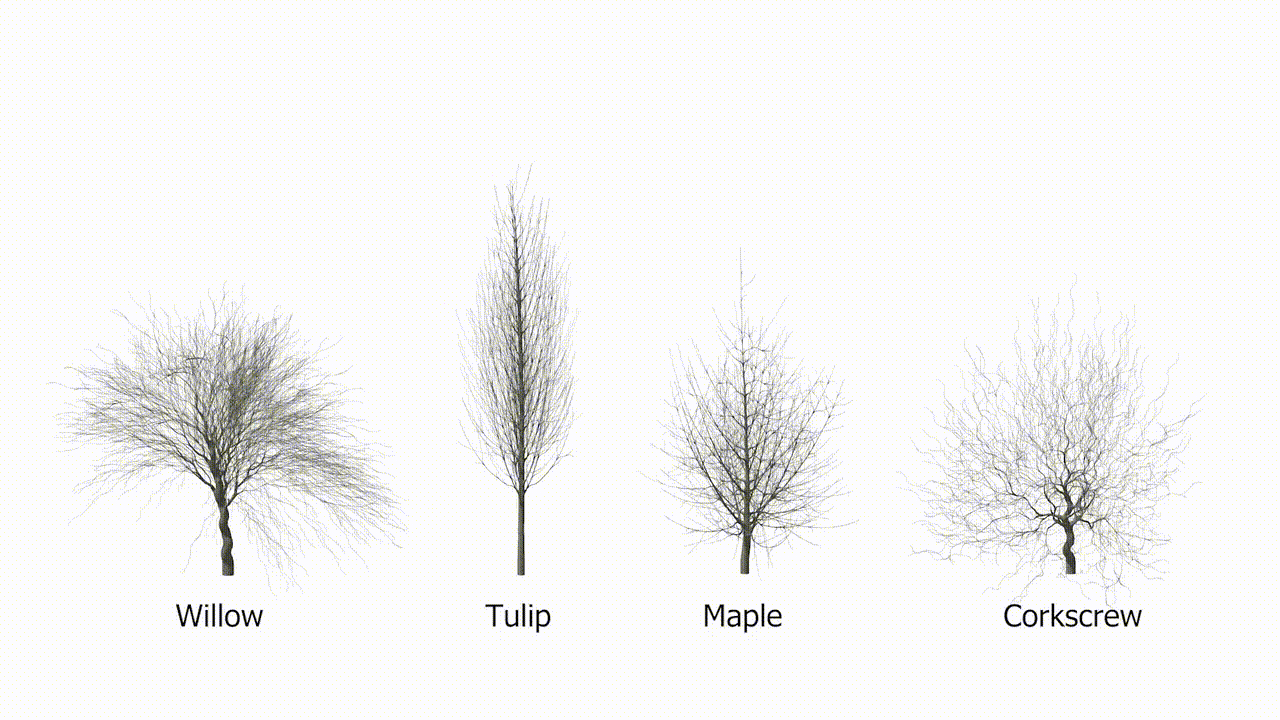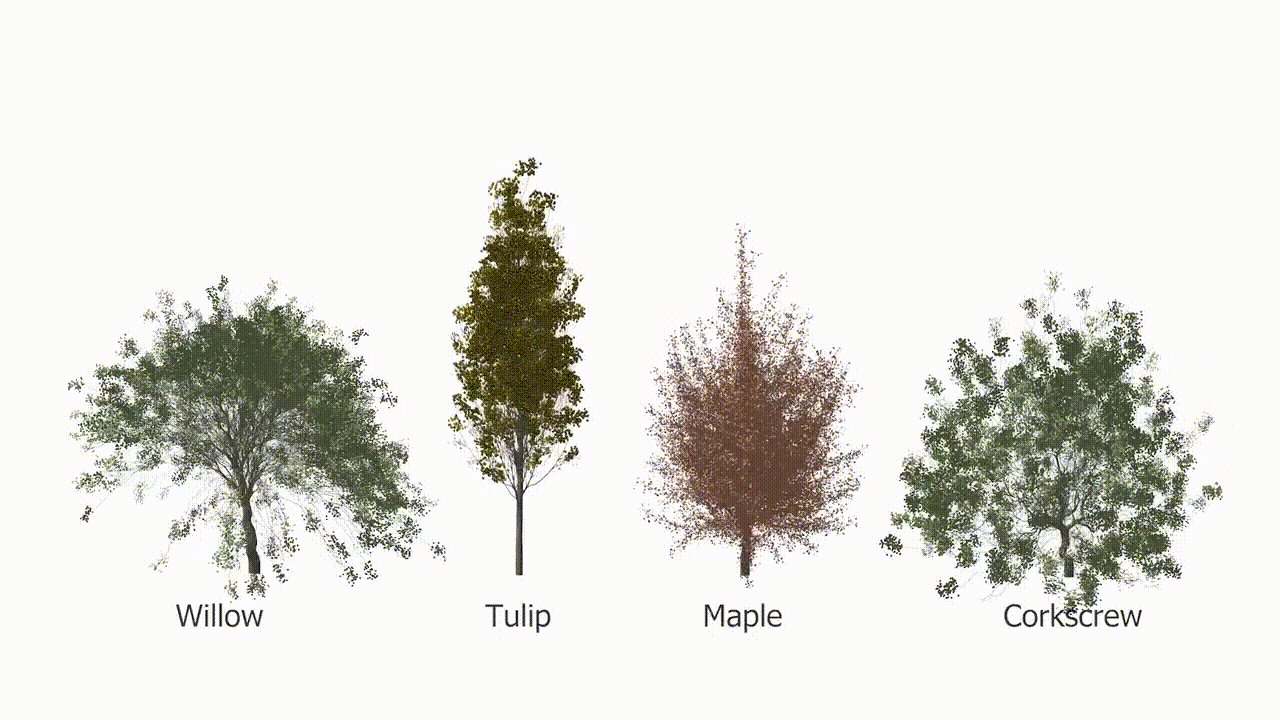
Afbeeldingscredits: Purdue/Bedrich Benes
Eén ding dat het AI-model zeker kan doen, is bomen laten groeien. Valse bomen. Onderzoekers van het Purdue Digital Forestry Institute (waar ik graag zou willen werken, bel mij) hebben een supercompact model gemaakt dat de groei van bomen op realistische wijze simuleert. Dit is een van die problemen die er eenvoudig uitzien, maar dat niet zijn; Natuurlijk kun je de groei van een werkende boom simuleren als je een game of film maakt, maar hoe zit het met serieus wetenschappelijk werk? “Hoewel AI schijnbaar alomtegenwoordig is geworden, is het tot nu toe vooral zeer succesvol gebleken in het modelleren van 3D-geometrieën die geen verband houden met de natuur”, zegt hoofdauteur Bedrich Benes.
Hun nieuwe model is slechts ongeveer een megabyte groot, wat extreem klein is voor een AI-systeem. Maar natuurlijk is DNA nog kleiner en dichter, en codeert voor de hele boom, van wortel tot knop. Het model werkt nog steeds in abstracties – het is geenszins een perfecte simulatie van de natuur – maar het laat zien dat de complexiteit van de boomgroei kan worden gecodeerd in een relatief eenvoudig model.
Eindelijk een robot van onderzoekers van de Universiteit van Cambridge die sneller braille kan lezen dan een mens, met een nauwkeurigheid van 90%. Waarom wil je dat weten? Eigenlijk is het niet voor blinden om het te gebruiken. Het team besloot dat dit een interessante en gemakkelijk te kwantificeren taak was om de gevoeligheid en snelheid van robotvingertoppen te testen. Als hij braille kan lezen door er gewoon overheen te zoomen, is dat een goed teken! Meer over deze interessante aanpak leest u hier. Of bekijk de onderstaande video: