AMD heeft tijdens het AMD Advanced AI-evenement van vandaag de motorkap van zijn volgende AI-acceleratorchip, de Instinct MI300, opgetild en het is een ongekend staaltje van 3D-integratie. De MI300, waarvan een versie wordt aangedreven door de El Capitan-supercomputer, is een complexe taart van computers, geheugen en communicatie die drie plakjes silicium hoog is en maar liefst 17 terabytes aan gegevens verticaal tussen die plakjes kan overbrengen. Het resultaat is een snelheidsverhoging van maar liefst 3,4x voor bepaalde berekeningen die cruciaal zijn voor machinaal leren. De chip biedt zowel contrasten als overeenkomsten met concurrerende benaderingen zoals Nvidia’s Grace Hopper-superchip en Intel’s Ponte Vecchio-supercomputerversneller.
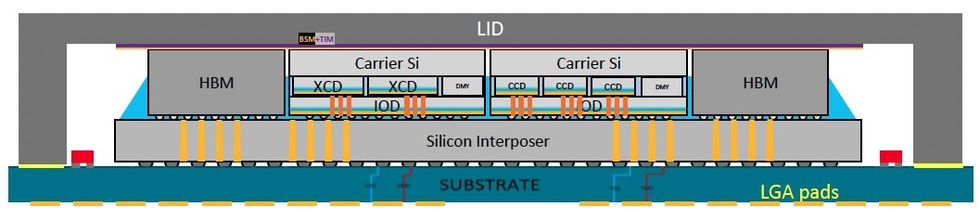
De MI300a stapelt drie CPU-chips (compute complex dies of CCD’s genoemd in AMD-jargon) en zes acceleratorchips (XCD’s) bovenop vier input-output dies (IOD’s), allemaal bovenop een stuk silicium dat ze met acht stapels verbindt. van DRAM met hoge bandbreedte rond de superchip. (De MI300x vervangt de CCD’s door nog twee XCD’s, voor een systeem met alleen een versneller.) Nu de schaling van de transistoren in het siliciumvlak vertraagt, wordt 3D-stapeling gezien als een sleutelmethode om meer transistors in hetzelfde gebied te krijgen en de wet van Moore verder te bevorderen. .
 Compute- en AI-chiplets zijn gestapeld bovenop de I/O- en cache-chiplets in de MI300a.AMD
Compute- en AI-chiplets zijn gestapeld bovenop de I/O- en cache-chiplets in de MI300a.AMD
“Het is werkelijk een ongelooflijke siliciumassemblage die de hoogste dichtheidsprestaties levert die de industrie op dit moment weet te produceren”, zegt Sam Naffziger, senior vice-president en bedrijfsmedewerker bij AMD. De integratie gebeurt met behulp van twee technologieën van Taiwan Semiconductor Manufacturing Co., SoIC (systeem op geïntegreerde chips) en CoWoS (chip op een wafer op een substraat). Deze laatste stapelt kleinere chips op grotere met behulp van hybride binding, waarbij de koperen pads op elke chip rechtstreeks met elkaar worden verbonden zonder te solderen. Het wordt gebruikt om AMD’s V-Cache te vervaardigen, een cache-uitbreidingschip die bovenop de geavanceerde CPU-chips wordt gestapeld. De eerste, CoWos, stapelt de chiplets op een groter stuk silicium, een zogenaamde interposer, dat is gebouwd om verbindingen met hoge dichtheid te bevatten.
Overeenkomsten en verschillen tussen AMD en Nvidia
Er zijn zowel overeenkomsten als verschillen in de aanpak van aartsrivaal Nvidia. Net zoals Nvidia deed met zijn Hopper-architectuur, voegde AMD’s acceleratorarchitectuur, CDNA3, de mogelijkheid toe om te rekenen met afgeknotte 32-bits getallen genaamd TF32 en met twee verschillende vormen van 8-bit drijvende-kommagetallen. Dit laatste kenmerk wordt gebruikt om de training van bepaalde delen van getransformeerde neurale netwerken, zoals grote taalmodellen, te versnellen. Beide bevatten ook een schema dat de omvang van het neurale netwerk verkleint, genaamd 4:2-sparsity.
Een andere overeenkomst is de opname van zowel CPU als GPU in hetzelfde pakket. In veel AI-computersystemen zijn de GPU en CPU afzonderlijk verpakte chips, geplaatst in een verhouding van 4 op 1. Een voordeel van het combineren ervan in één superchip is dat zowel de CPU als de GPU toegang hebben tot dezelfde cache met hoge bandbreedte en DRAM (HBM) zodanig dat ze elkaar niet hinderen tijdens het lezen en schrijven van gegevens. .
Nvidia’s Grace Hopper is zo’n superchipcombinatie die de Grace CPU verbindt met de Hopper GPU via Nvidia NVLink Chip-2-Chip-interconnects. AMD’s MI300a is dat ook, met drie CPU-chips die zijn ontworpen voor de Genoa-lijn en zes XCD-accelerators die gebruik maken van de AMD Infinity Fabric-verbindingstechnologie.
Maar een nonchalante blik op de Grace Hopper en de MI300 onthult enkele diepgaande verschillen. Grace en Hopper zijn elk één chip die alle noodzakelijke functionele blokken van het systeem op een chip integreert: rekenkracht, I/O en cache. Ze zijn horizontaal met elkaar verbonden en zijn groot – bijna op de grens van de omvang van de fotolithografische technologie.
AMD koos voor een andere aanpak, een aanpak die het gedurende verschillende generaties van zijn CPU’s volgde en die rivaal Intel gebruikte voor zijn Ponte Vecchio 3D-supercomputerversneller. Het concept heet systeem-technologie-co-optimalisatie, of STCO. Dit betekent dat de ontwerpers begonnen met het opdelen van de chip in zijn functies en besloten welke functies welke productietechnologie nodig hadden.
 Een stuk MI300 siliconen overlay voor de montage aan de bovenkant van de soldeerbal aan de onderkant van de verpakking.AMD
Een stuk MI300 siliconen overlay voor de montage aan de bovenkant van de soldeerbal aan de onderkant van de verpakking.AMD
“Wat we met de MI300 wilden doen, was uitbreiden wat mogelijk was in een monolithische GPU. Dus hebben we het stukje bij beetje gedeconstrueerd en vervolgens opnieuw opgebouwd”, zegt Alan Smith, Senior Associate en Chief Architect voor Instinct. Hoewel het dit al verschillende generaties CPU’s doet, is de MI300 de eerste keer dat een bedrijf GPU-chips heeft gebouwd en deze in één systeem heeft gebundeld.
“Door de GPU in chiplets op te delen, konden we de computer in het meest geavanceerde verwerkingsknooppunt plaatsen, terwijl de rest van de chip in een technologie bleef die beter geschikt was voor cache en I/O”, zegt hij. In het geval van de MI300 is de hele computer gebouwd met behulp van het N5-proces van TSMC, het meest geavanceerde proces dat beschikbaar is en dat wordt gebruikt voor de hoogwaardige GPU’s van Nvidia. Noch de I/O-functies, noch de systeemcache profiteren van de N5, dus AMD koos voor een goedkopere technologie (N6). Daarom kunnen de twee functies samen op dezelfde chiplet worden gebouwd.
Nu de functies gescheiden zijn, zijn alle stukjes silicium in de MI300 klein. De grootste, de I/O-matrices, zijn nog niet eens half zo groot als de Hopper. En CCD’s zijn slechts ongeveer een vijfde van de grootte van een I/O-chip. Kleine maten maken een groot verschil. Over het algemeen geven kleinere chips een betere opbrengst. Dat wil zeggen, een enkele dobbelsteen zal een groter aandeel werkende kleine chips opleveren dan grote chips. “3D-integratie is niet gratis”, zegt Naffziger. Maar de hogere opbrengst compenseert de kosten, zegt hij.
Geluk en ervaring
Het ontwerp omvatte slim hergebruik van bestaande technologieën en ontwerpen, een paar compromissen en een beetje geluk, aldus Naffziger, een IEEE Fellow. In twee gevallen heeft hergebruik plaatsgevonden. Ten eerste was AMD in staat om de 3D-integratie met een zekere mate van vertrouwen uit te voeren, omdat het al exact dezelfde hoogte aan verticale verbindingen – 9 micrometer – gebruikte in zijn V-cache-product.
Als optionele add-on waar AMD extra voor zou kunnen vragen, biedt V-cache weinig risico op slechte prestaties of andere problemen die een grote impact hebben op het bedrijf. “Het was geweldig dat we hierdoor de productieproblemen en alle ontwerpcomplexiteit van 3D-stapelen konden oplossen zonder de hoofdproductlijn in gevaar te brengen”, zegt Naffziger.
Het tweede hergebruikgeval was een beetje een gok. Toen het MI300-team besloot dat een CPU/GPU-combinatie nodig was, vroeg Naffziger “enigszins schaapachtig” aan het hoofd van het team dat de Zen4 CCD voor de CPU in Genua ontwierp of de CCD gemaakt kon worden om aan de behoeften van de MI300 te voldoen. Dat team stond onder druk om de deadline eerder dan verwacht te halen, maar reageerde een dag later. Naffziger had geluk; De Zen4 CCD had een kleine opening op precies de juiste plaats om verticale verbindingen te maken met de MI300 I/O-chip en de bijbehorende circuits zonder het algehele ontwerp te verstoren.
Er moest echter nog wat geometrie worden uitgewerkt. Om alle interne communicatie te laten werken, moesten de vier I/O-chips op een bepaalde rand tegenover elkaar staan. Dit betekende dat er een spiegelversie van de chiplet moest worden gemaakt. Omdat het in code is ontworpen met een I/O-chiplet, zijn XCD en zijn verticale links gebouwd om verbinding te maken met beide versies van I/O. Maar er was geen gedoe met CCD, wat ze gelukkig al hadden. In plaats daarvan werd de I/O ontworpen met redundante verbindingen, dus ongeacht op welke versie van de chiplet deze zich bevond, de CCD zou verbinding maken.
 Om alles te evenaren, moesten de IOD-chips als spiegels van elkaar worden gemaakt en moesten de accelerator- (XCD) en computer- (CCD) chips worden geroteerd.AMD
Om alles te evenaren, moesten de IOD-chips als spiegels van elkaar worden gemaakt en moesten de accelerator- (XCD) en computer- (CCD) chips worden geroteerd.AMD
Het elektriciteitsnet, dat honderden ampère stroom moet leveren aan de computerchips bovenop de stapel, stond voor soortgelijke uitdagingen omdat ook het alle verschillende chipletoriëntaties moest accommoderen, merkte Naffziger op.
Uit artikelen op uw website
Gerelateerde artikelen op internet