Generatieve AI is de meest veeleisende vorm van AI van dit moment en is de drijvende kracht achter chatbots als ChatGPT, Ernie, LLaMA, Claude en Cohere, evenals beeldgeneratoren als DALL-E 2, Stable Diffusion, Adobe Firefly en Midjourney. Genatieve AI is een tak van AI waarmee machines patronen kunnen leren uit enorme datasets en vervolgens autonoom nieuwe inhoud kunnen produceren op basis van die patronen. Hoewel generatieve AI vrij nieuw is, zijn er al veel voorbeelden van modellen die tekst, afbeeldingen, video en audio kunnen produceren.
Veel zogenaamde fundamentele modellen zijn getraind op voldoende gegevens om competent te zijn in een breed scala aan taken. Een groot taalmodel kan bijvoorbeeld essays, computercode, recepten, eiwitstructuren, grappen, medisch diagnostisch advies en meer genereren. In theorie kan het ook instructies genereren voor het bouwen van een bom of het maken van een biologisch wapen, hoewel veiligheidsmaatregelen dergelijk misbruik moeten voorkomen.
Wat is het verschil tussen AI, machine learning en generatieve AI?
Kunstmatige intelligentie (AI) verwijst naar een breed scala aan computationele benaderingen om menselijke intelligentie na te bootsen. Machine learning (ML) is een subset van AI; richt zich op algoritmen die systemen in staat stellen om van data te leren en hun prestaties te verbeteren. Vóór de komst van generatieve kunstmatige intelligentie leerden de meeste ML-modellen van datasets om taken uit te voeren zoals classificatie of voorspelling. Generatieve AI is een gespecialiseerd type ML waarbij modellen betrokken zijn die de taak vervullen om nieuwe inhoud te genereren en zich op het gebied van creativiteit te begeven.
Welke architecturen gebruiken generatieve AI-modellen?
Generatieve modellen worden gebouwd met behulp van verschillende neurale netwerkarchitecturen – in wezen het ontwerp en de structuur die bepalen hoe het model is georganiseerd en hoe informatie er doorheen stroomt. Enkele van de meest bekende architecturen zijn variatieve auto-encoders (VAE’s), generatieve vijandige netwerken (GAN’s) en transformatoren. De transformatorarchitectuur, die voor het eerst werd geschetst in dit baanbrekende Google-paper uit 2017, vormt de drijvende kracht achter de grote taalmodellen van vandaag. De transformatorarchitectuur is echter minder geschikt voor andere vormen van generatieve AI, zoals beeld- en geluidsgeneratie.
Autoencoders leren efficiënte gegevensrepresentaties via het encoder-decoder-framework. De encoder comprimeert de invoergegevens in een lagerdimensionale ruimte, bekend als latente (of ingebedde) ruimte, waarin de belangrijkste aspecten van de gegevens worden opgeslagen. De decoder kan deze gecomprimeerde representatie vervolgens gebruiken om de originele gegevens te reconstrueren. Zodra de autoencoder op deze manier is getraind, kan deze de nieuwe invoer gebruiken om wat hij als passende uitvoer beschouwt te genereren. Deze modellen worden vaak gebruikt in beeldvormingshulpmiddelen en hebben ook toepassing gevonden bij de ontdekking van geneesmiddelen, waar ze kunnen worden gebruikt om nieuwe moleculen met gewenste eigenschappen te genereren.
Bij generatieve vijandige netwerken (GAN’s) is bij training sprake van een generator en een discriminator die als tegenstanders kunnen worden beschouwd. De generator heeft tot doel realistische gegevens te produceren, terwijl de discriminator tot doel heeft onderscheid te maken tussen de gegenereerde outputs en de daadwerkelijke ‘grondwaarheid’-outputs. Elke keer dat de discriminator de gegenereerde output opvangt, gebruikt de generator die feedback om de kwaliteit van zijn output te verbeteren. Maar de discriminator krijgt ook feedback op zijn prestaties. Deze tegengestelde interactie resulteert in de verfijning van beide componenten, wat leidt tot het creëren van steeds authentiekere inhoud. GAN’s staan vooral bekend om het creëren van deepfakes, maar ze kunnen ook worden gebruikt voor meer goedaardige vormen van beeldgeneratie en vele andere toepassingen.
Transformer is misschien wel de regerend kampioen van generatieve AI-architecturen vanwege de alomtegenwoordigheid ervan in de krachtige Large Language Models (LLM) van vandaag. De kracht ervan ligt in het aandachtsmechanisme, waardoor het model zich kan concentreren op verschillende delen van de invoerreeks terwijl het voorspellingen doet. In het geval van taalmodellen bestaat de invoer uit reeksen woorden die zinnen vormen, en voorspelt de transformator welke woorden daarna zullen komen (we zullen hieronder meer in detail treden). Bovendien kunnen transformatoren alle array-elementen parallel verwerken in plaats van er van begin tot eind doorheen te marcheren, zoals eerdere modeltypen deden; deze parallellisatie maakt training sneller en efficiënter. Toen ontwikkelaars enorme hoeveelheden tekst toevoegden om transformatoren voor het leren te modelleren, ontstonden de opmerkelijke chatbots van vandaag.
Hoe werken grote taalmodellen?
Een op transformatoren gebaseerde LLM wordt getraind door hem te voorzien van een enorme dataset met tekst waaruit hij kan leren. Het aandachtsmechanisme speelt een rol bij het verwerken van zinnen en het zoeken naar patronen. Door alle woorden in een zin tegelijk te bekijken, begint hij geleidelijk aan te begrijpen welke woorden het vaakst bij elkaar voorkomen en welke woorden het belangrijkst zijn voor de betekenis van de zin. Het leert deze dingen door te proberen het volgende woord in een zin te voorspellen en de gok ervan te vergelijken met de grondwaarheid. De fouten ervan fungeren als feedbacksignalen die ervoor zorgen dat het model de gewichten die het aan verschillende woorden toekent, aanpast voordat het opnieuw probeert.
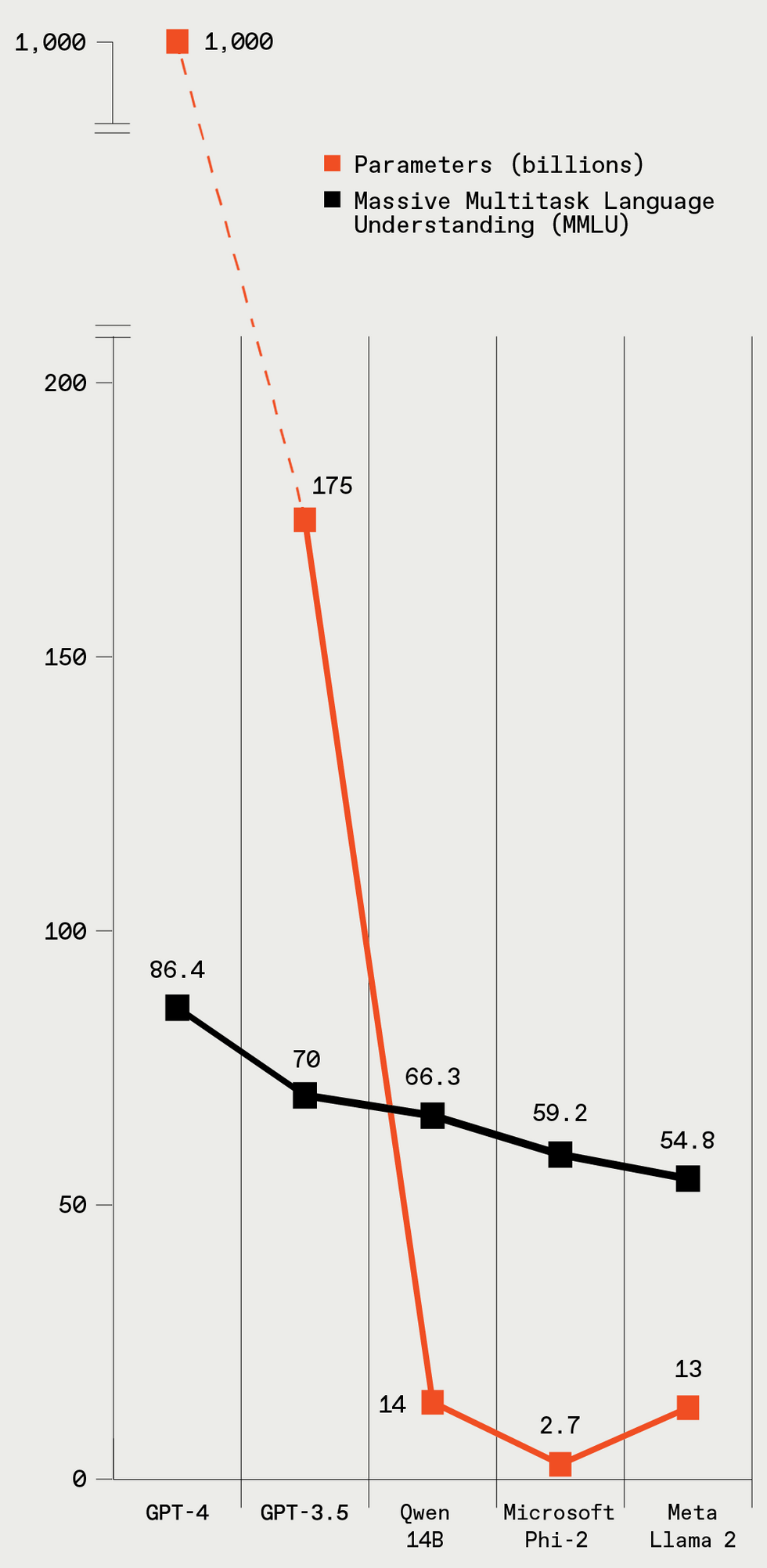 Deze vijf LLM’s variëren sterk in grootte (uitgedrukt in parameters), waarbij grotere modellen beter presteren op de standaard LLM-benchmarktest. IEEE-spectrum
Deze vijf LLM’s variëren sterk in grootte (uitgedrukt in parameters), waarbij grotere modellen beter presteren op de standaard LLM-benchmarktest. IEEE-spectrum
Om het trainingsproces in enigszins technische termen uit te leggen, wordt de tekst in de trainingsgegevens opgesplitst in elementen die tokens worden genoemd. Dit zijn woorden of delen van woorden, maar laten we voor de eenvoud zeggen dat alle tokens woorden zijn. Terwijl het model de zinnen in de trainingsgegevens doorneemt en de relaties tussen de tokens leert, creëert het voor elk getal een lijst met getallen, een zogenaamde vector. Alle getallen in de vector vertegenwoordigen verschillende aspecten van het woord: de semantische betekenis ervan, de relatie met andere woorden, de gebruiksfrequentie, enz. Soortgelijke woorden, zoals elegant En modieus, zullen vergelijkbare vectoren hebben en zullen ook dicht bij elkaar liggen in de vectorruimte. Deze vectoren worden woordinbedding genoemd. De LLM-parameters omvatten gewichten die verband houden met alle woordinsluitingen en het aandachtsmechanisme. Het gerucht gaat dat GPT-4, het OpenAI-model dat als de huidige kampioen wordt beschouwd, meer dan 1 biljoen parameters heeft.
Met voldoende gegevens en trainingstijd begint LLM de subtiliteiten van de taal te begrijpen. Hoewel een groot deel van de training bestaat uit het zin voor zin bekijken van tekst, legt het aandachtsmechanisme ook de relaties tussen woorden vast in een langere tekstreeks van vele alinea’s. Zodra de LLM is getraind en klaar voor gebruik, speelt het aandachtsmechanisme nog steeds. Wanneer het model tekst genereert als antwoord op een vraag, gebruikt het zijn voorspellende krachten om te beslissen wat het volgende woord zou moeten zijn. Bij het genereren van langere stukken tekst voorspelt het het volgende woord in de context van alle woorden die het tot nu toe heeft geschreven; deze eigenschap vergroot de samenhang en continuïteit van haar schrijven.
Waarom hallucineren grote taalmodellen?
Je hebt misschien gehoord dat LLM’s soms ‘hallucineren’. Dat is een beleefde manier om te zeggen dat ze de zaken heel overtuigend verzinnen. Het model genereert soms tekst die past bij de context en grammaticaal correct is, maar de stof is verkeerd of onzinnig. Deze slechte gewoonte komt voort uit het trainen van LLM’s met enorme hoeveelheden gegevens die van internet worden gehaald, waarvan er vele feitelijk niet accuraat zijn. Omdat het model eenvoudigweg probeert het volgende woord in de reeks te voorspellen op basis van wat het heeft gezien, kan het plausibele tekst genereren die geen basis heeft in de werkelijkheid.
Waarom is generatieve AI controversieel?
Een bron van controverse over generatieve AI is de oorsprong van de trainingsgegevens. De meeste AI-bedrijven die grote modellen trainen om tekst, afbeeldingen, video en audio te genereren, zijn niet transparant geweest over de inhoud van hun trainingsdatasets. Uit verschillende lekken en experimenten is gebleken dat deze datasets auteursrechtelijk beschermd materiaal bevatten, zoals boeken, krantenartikelen en films. Er lopen een aantal rechtszaken om te bepalen of het gebruik van auteursrechtelijk beschermd materiaal om AI-systemen te trainen een redelijk gebruik is, of dat AI-bedrijven auteursrechthouders moeten betalen voor het gebruik van hun materiaal.
In deze zin zijn veel mensen bezorgd dat het wijdverbreide gebruik van generatieve AI de banen zal wegnemen van creatieve mensen die kunst, muziek, geschreven werken, enzovoort maken. En mogelijk ook van mensen die een breed scala aan banen uitoefenen, waaronder vertalers, paralegals, vertegenwoordigers van de klantenservice en journalisten. Er hebben al een paar zorgwekkende ontslagen plaatsgevonden, maar het is nog steeds moeilijk te zeggen of generatieve AI betrouwbaar genoeg zal zijn voor grote zakelijke toepassingen. (Zie hierboven over hallucinaties.)
Ten slotte bestaat het gevaar dat generatieve AI wordt gebruikt om slechte dingen te maken. Natuurlijk zijn er veel categorieën van slechte dingen waarvoor ze theoretisch kunnen worden gebruikt. Generatieve AI kan worden gebruikt voor gepersonaliseerde oplichting en phishing-aanvallen: met behulp van ‘stemklonen’ kunnen fraudeurs bijvoorbeeld de stem van een specifieke persoon kopiëren en de familie van die persoon bellen om hulp (en geld) te vragen. Alle formaten van generatieve kunstmatige intelligentie – tekst, audio, beeld en video – kunnen worden gebruikt om desinformatie te genereren door plausibele representaties te creëren van dingen die nooit zijn gebeurd, een bijzonder zorgwekkende mogelijkheid als het om verkiezingen gaat. (Ondertussen, zoals Spectrum Deze week aangekondigd heeft de Amerikaanse Federal Communications Commission gereageerd door robocalls, gegenereerd door kunstmatige intelligentie, te verbieden.) Tools om afbeeldingen en video’s te genereren kunnen worden gebruikt om pornografie te produceren zonder toestemming, hoewel de tools van grote bedrijven dergelijk gebruik niet toestaan. En chatbots kunnen in theorie een potentiële terrorist door de stappen leiden van het maken van een bom, zenuwgas en tal van andere verschrikkingen. Hoewel grote LLM’s veiligheidsmaatregelen hebben getroffen om dergelijk misbruik te voorkomen, omzeilen sommige hackers deze veiligheidsmaatregelen graag. Bovendien bestaan er “ongecensureerde” versies van open source LLM’s.
Ondanks dergelijke potentiële problemen denken veel mensen dat generatieve AI mensen ook productiever kan maken en kan worden gebruikt als hulpmiddel om geheel nieuwe vormen van creativiteit mogelijk te maken. We zullen waarschijnlijk zowel rampen als creatieve bloei meemaken en nog veel meer dat we niet verwachten. Maar het kennen van de basisprincipes van hoe deze modellen werken, wordt tegenwoordig steeds belangrijker voor technisch onderlegde mensen. Want hoe geavanceerd deze systemen ook worden, het is de taak van mensen om ze draaiende te houden, de volgende beter te maken en, met een beetje geluk, ook mensen te helpen.